Summary
Data Mesh is rapidly redefining how organizations think about scaling data architectures. With traditional centralized data platforms struggling under the weight of exponential growth, the need for a decentralized, domain-oriented approach has become urgent. This blog explores the core principles of Data Mesh, why it’s gaining momentum in modern enterprises and scalable data architecture, and how it offers scalable, agile, and business-aligned architectures to unlock the true value of data.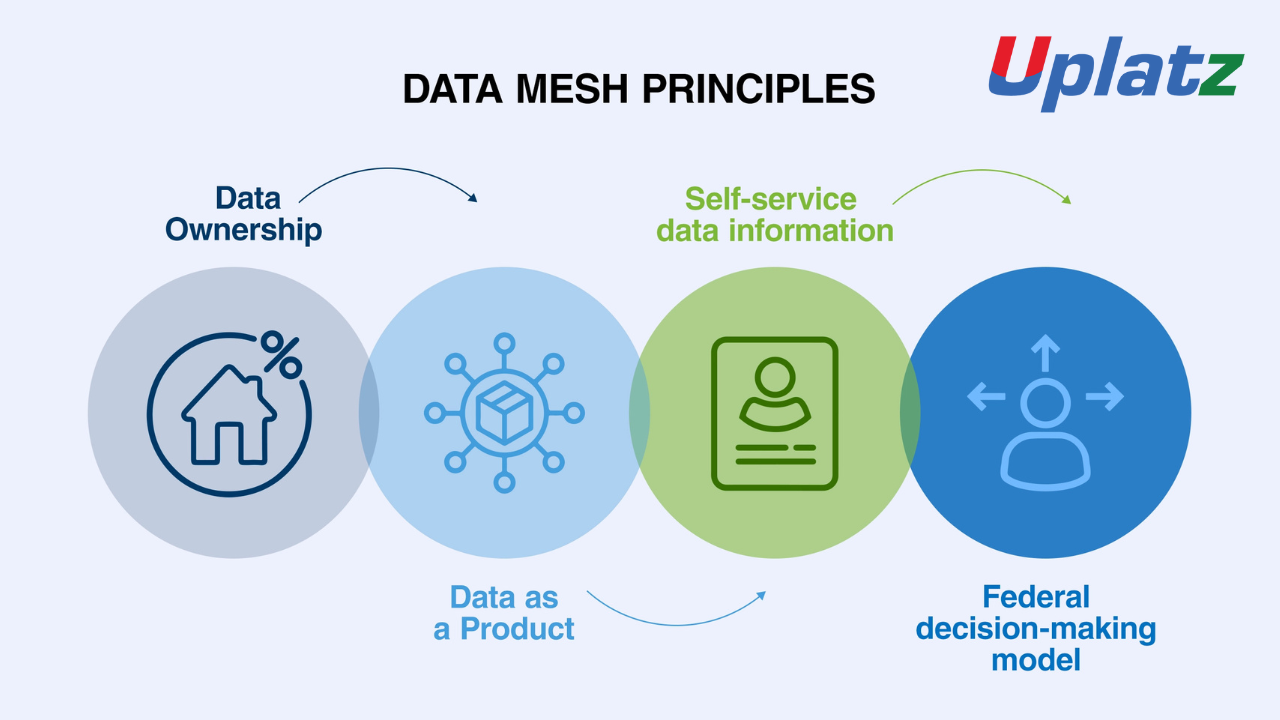
Career Path – Data Engineer by uplatz
Introduction
As businesses increasingly rely on data to drive decisions, innovation, and customer experiences, the limitations of centralized data platforms have become glaringly evident. Traditional monolithic architectures like data lakes and warehouses are often slow to adapt, require specialized teams for maintenance, and can’t keep up with real-time demands—especially when a truly scalable data architecture is needed to support rapid growth and agility.
Enter Data Mesh—a paradigm shift that treats data as a product and distributes ownership across domain-specific teams. It blends organizational transformation with technical design, empowering cross-functional teams to build, share, and scale data products autonomously.
In fact, many forward-thinking teams are strengthening their capabilities through training like Data Engineering with Uplatz, which covers Data Mesh, data pipelines, and scalable architectures in depth.
This blog delves into why Data Mesh is becoming the go-to architectural approach for modern enterprises seeking scalable data architecture, resilience, and business-aligned infrastructures.
Why Traditional Data Architectures Fall Short
Centralized data platforms were built to streamline data storage, but they’re increasingly being pushed to the breaking point. Key challenges include:
-
Bottlenecks in Central Teams: Central data teams are overwhelmed by requests from every department, delaying insights.
-
Data Silos and Inconsistency: Merging data across teams often results in inconsistent definitions, duplication, and delays.
-
Scalability Issues: Centralized systems struggle to scale as data volume, velocity, and variety grow exponentially.
-
Lack of Domain Context: Centralized pipelines often miss the domain-specific nuances required for accurate analytics.
These pain points create operational inefficiencies and prevent organizations from becoming truly data-driven.
What Is Data Mesh?
Data Mesh is a decentralized approach to data architecture that aligns closely with the principles of domain-driven design. It decentralizes data ownership to business domains and treats data as a product, managed by cross-functional teams who own the full lifecycle—from ingestion to delivery.
The Four Pillars of Data Mesh
-
Domain-Oriented Ownership
Data responsibility is pushed to the teams who generate and use it, ensuring deep context and faster turnaround. -
Data as a Product
Each data set is treated as a consumable product, with quality, discoverability, and usability at the forefront. -
Self-Serve Data Infrastructure
Platform teams provide tools and automation that enable domain teams to easily build and manage their data pipelines. -
Federated Computational Governance
A collaborative governance model ensures consistency and compliance without centralized bottlenecks.
Why Data Mesh Is Gaining Ground
Organizations are embracing Data Mesh for several compelling reasons:
Scalability Through Decentralization
Decentralized ownership reduces pressure on central teams and allows parallel development and scaling across domains.
Faster Time-to-Insight
Domain teams build and manage their own data products, eliminating handoff delays and accelerating access to insights.
Improved Data Quality
Data owners are held accountable for data quality, ensuring better documentation, observability, and trust in data assets.
Organizational Agility
By breaking the monolith, teams can evolve independently, adapt faster, and innovate without being constrained by central roadmaps.
Closer Business Alignment
Domain-oriented data models are naturally more aligned with business objectives, KPIs, and workflows.
Architecting a Data Mesh System
Implementing Data Mesh is not a pure technical exercise—it’s an organizational transformation. Here’s how enterprises are getting started:
Identify and Empower Domains
Map out domain boundaries (e.g., Sales, Marketing, Finance) and assign data product owners responsible for delivery and quality.
Build a Self-Serve Data Platform
Develop infrastructure-as-a-platform using technologies like Kubernetes, Airflow, dbt, and Lakehouse architectures.
Standardize Data Contracts and Interfaces
Use APIs and schema registries to define clear contracts between producers and consumers.
Implement Federated Governance
Adopt cross-domain policies for access control, lineage tracking, and compliance—without central micromanagement.
Common Use Cases of Data Mesh
-
E-commerce: Teams manage product, customer, and order data independently to power personalization and inventory systems.
-
Banking: Domain-specific models for risk, fraud, and transaction data enable faster compliance reporting.
-
Healthcare: Decentralized patient data products support real-time analytics and personalized care.
Challenges and Considerations
While promising, Data Mesh comes with its own set of complexities:
-
Cultural Shift: Moving from centralized control to shared responsibility requires deep organizational change.
-
Tooling Gaps: Many tools are still evolving to fully support decentralized data product workflows.
-
Governance Balance: Too much autonomy can lead to chaos; too much control negates the benefits of decentralization.
-
Onboarding and Training: Teams need support to understand data product principles and build platform competencies.
The Future of Scalable Data Architectures
As AI, real-time analytics, and hyper-personalized services become the norm, traditional data architectures will continue to falter. Data Mesh offers a scalable, flexible solution that grows with your organization—technically and culturally.
Forward-thinking companies are already making the shift, investing in platform engineering, data product teams, and federated governance models to stay competitive and resilient.
Conclusion
Data Mesh is not just a trend—it’s a transformative movement. By reimagining data as a decentralized product ecosystem, it solves the scaling, agility, and collaboration issues that have plagued centralized architectures for decades.
In an era where data is the lifeblood of innovation, Data Mesh empowers organizations to harness that data faster, smarter, and at scale.
References
-
Zhamak Dehghani (2020). Data Mesh: Delivering Data-Driven Value at Scale
https://martinfowler.com/articles/data-monolith-to-mesh.html -
ThoughtWorks (2021). What is Data Mesh?
https://www.thoughtworks.com/en-in/insights/blog/data-mesh-principles-and-architecture -
Gartner (2023). Top Trends in Data Management and Analytics
https://www.gartner.com/en/articles/data-and-analytics-trends -
InfoQ (2022). Implementing a Data Mesh in Practice
https://www.infoq.com/articles/data-mesh-practical-guide/ -
Starburst (2023). The Rise of Data Mesh – What You Need to Know
https://www.starburst.io/info/what-is-data-mesh